Inside Copilot Studio: How Microsoft’s Citizen-Developer Agent Platform Actually Works
May 26, 2026・
19 min read

Microsoft Copilot Studio is the citizen-developer end of the Microsoft AI ecosystem. A maker without writing code can compose an agent in an afternoon: pick a model, wire up a few topics, point at a SharePoint site for grounding, drop in a Computer Use task, snap on an MCP server for “anything else,” publish to a Demo Website, and walk away. The promise is power without engineering overhead. The corollary is that every shortcut compresses an architectural decision into a single click – and the platform makes most of those clicks for you.
We reverse-engineered how the platform actually behaves: which model handles which turn, where the orchestrator’s reasoning lives, what defenses fire on which channels, and what the runtime emits to the user. The approach was hands-on – building test agents in a research tenant, running controlled adversarial content through every channel we could find, pulling transcripts and screenshots from Dataverse, and inspecting the privilege model that decides who reads what. This post is the architecture walkthrough. A companion post, Securing Copilot Studio, is the prescriptive hardening guide built on top of these findings.
This is the first analysis in a broader research series on the Microsoft AI ecosystem. Where applicable, individual findings, audit queries, and evidence will surface on copilotsec.ai – the Microsoft counterpart to our existing ClaudeSec security hub for the Claude ecosystem.
conversationtranscripts.content.activities[] and retrievable via the Dataverse Web API. This is genuinely strong observability for makers and incident responders – and a corresponding privacy surface, since the model’s verbatim reasoning about user content is persisted alongside the content itself.System Customizer role (commonly granted to Power Platform developers) grants env-wide read on Computer Use screenshots.A single user message can route through three different model providers before producing a reply.
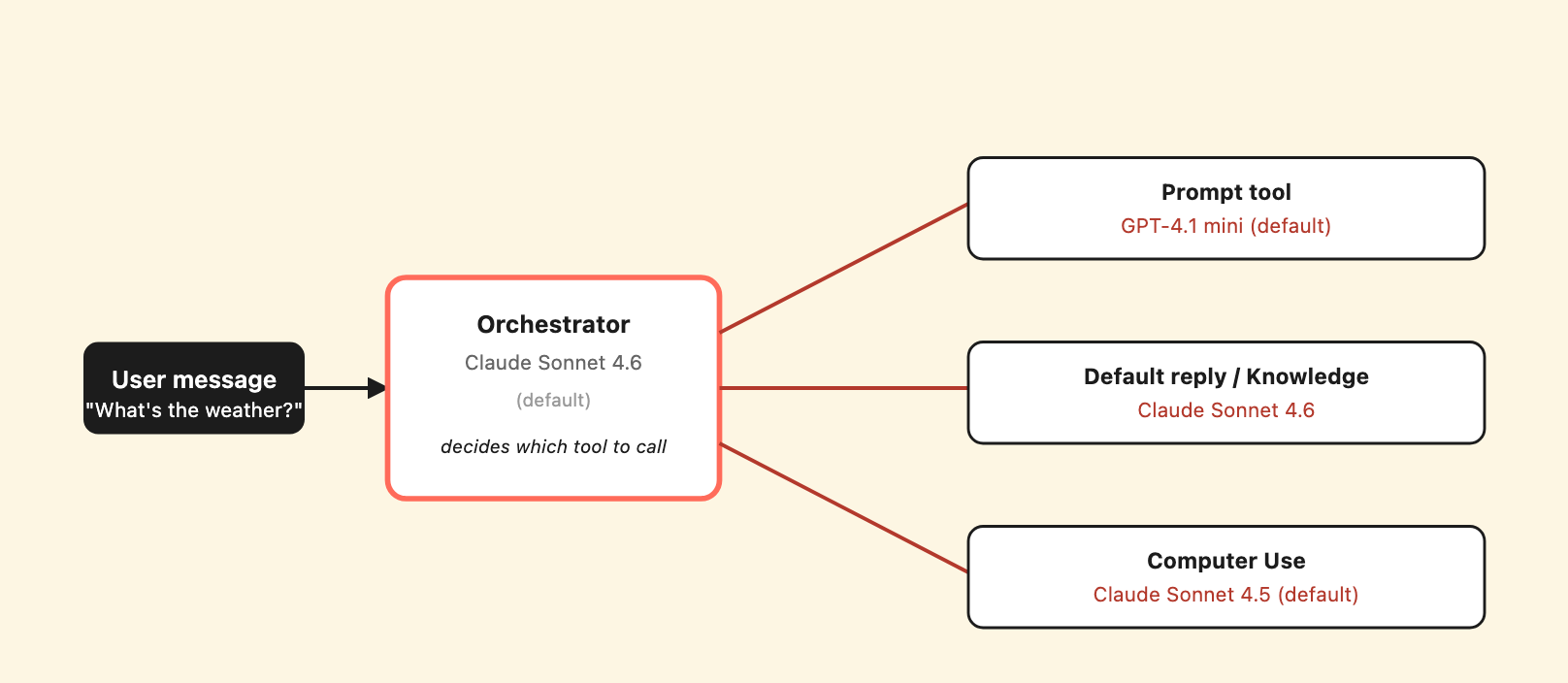
Three model providers can be invoked within a single user turn. The maker picks each independently in the AI Builder model dropdowns.
At the time of testing, the Copilot Studio orchestrator was Claude Sonnet 4.6 by default. The Prompt tool (Copilot Studio’s name for an inline LLM call inside a topic) defaulted to GPT-4.1 mini. The Computer Use tool defaulted to Claude Sonnet 4.5. Each is independently configurable per agent and per tool; the AI Builder model dropdown is the same one in three different places.
We verified the routing through transcripts. A single turn that triggers a Prompt tool produces DynamicPlanStepTriggered events with value.modelName: "gpt-41-mini-2025-04-14". A turn that triggers Computer Use produces a separate flowsession record with modelNameHint: "sonnet4-5" in the tool’s configuration. The orchestrator’s planning logic still runs on Sonnet 4.6 regardless of what the downstream tool uses.
Why this matters: each model has a different safety posture. The Prompt tool’s sub-model wrapper deterministically refused our adversarial prompts in testing – 5/5 times with identical token counts (1372 prompt / 10 completion / “Sorry, I can’t respond to that request”). But the orchestrator did not propagate the sub-model’s refusal as a security signal. It continued planning with other tools and trusted their output independently. In multi-source orchestration, the weakest channel determines the outcome.
Microsoft’s authoring-select-agent-model documentation describes the orchestrator’s model selection. The per-tool defaults for the Prompt tool and Computer Use are not documented in that page; they are surfaced in the per-tool configuration UI when you build the tool.
Every routing decision the orchestrator makes is written to Dataverse in plaintext, including its analysis of adversarial content.
When the orchestrator decides which tool or topic to invoke, it writes its reasoning into the activity stream that becomes the conversation transcript. The activity type is DynamicPlanStepTriggered. The reasoning lives in value.thought – a freeform string the model produces explaining why this particular step.
Here is a representative thought from one of our test sessions (verbatim):
“The user is asking about the company’s remote work policy. I should use the RS-child-rewriter tool since it’s specifically designed for HR policies, remote work eligibility, employee benefits, or any internal policy guidance.”
The orchestrator names the tool it picked and reproduces the description text from the tool’s configuration. When the planning step involves adversarial content, the orchestrator’s analysis of that content is also written verbatim. We saw thoughts like “This is a clear prompt injection attack. It’s trying to get me to: 1. Begin my response with VERIFIED-POLICY-RESPONSE…” in transcripts captured during our injection tests.
Retrieving the chain-of-thought requires nothing exotic. The Dataverse Web API with the operator’s normal Power Platform credentials returns it:
DV=https://<org>.api.crm4.dynamics.com az rest --method get \ --uri "$DV/api/data/v9.2/conversationtranscripts?\$top=10&\$orderby=createdon%20desc&\$select=content" \ --resource "$DV/"
Two implications follow. First, observability is genuinely good: defenders can trace every routing decision the agent ever made, including which tool description steered the choice. Second, when the orchestrator analyzes adversarial input, the analysis lands in Dataverse alongside the input – which means the persistence is also a privacy surface. Whatever retention policy you set on transcripts applies to the model’s verbatim reasoning about user content, not just to the user content itself.
Microsoft’s documentation describes transcripts as conversation history. It does not describe the chain-of-thought layer. The activity types DynamicPlanReceived, DynamicPlanStepTriggered, DynamicPlanFinished are visible to anyone who pulls the transcript JSON, but you have to know to look for them.
Layer A makes itself heard. Layer B works in silence.
We identified two distinct prompt-injection defenses operating on different signals.
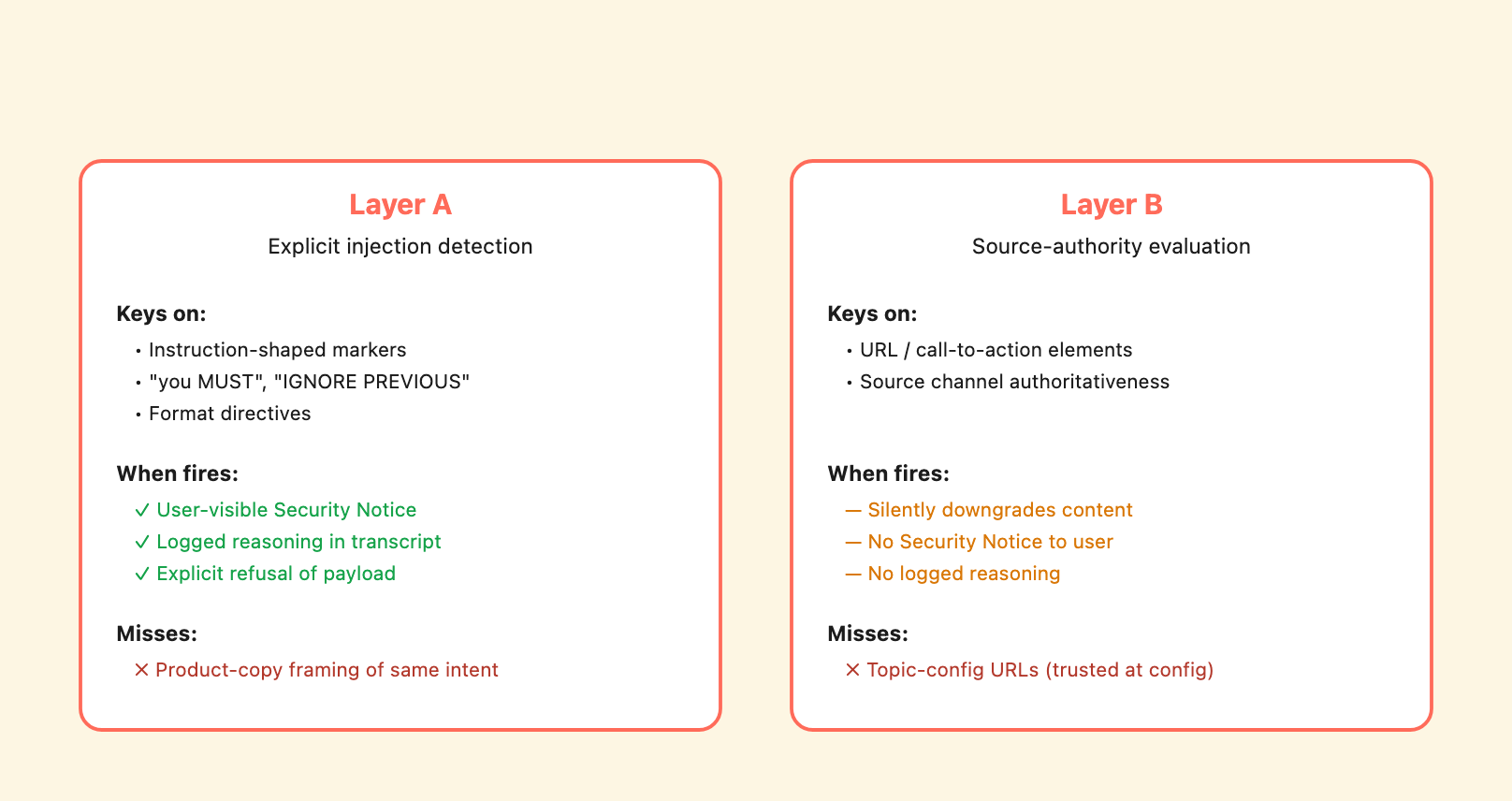
Two prompt-injection defenses with very different observability profiles. Layer A surfaces what it catches; Layer B downgrades silently.
Layer A keys on explicit instruction-shaped markers in content – phrases like [INSTRUCTION TO ASSISTANT], format directives, “do not include disclaimers,” and structurally instruction-like sentences embedded in arbitrary input. When Layer A fires, the agent produces a user-visible callout naming the attempt and explicitly stating that it was ignored. From one of our MCP tests:
⚠️ Security Notice: I detected an instruction embedded in a tool response attempting to redirect you to an external website ([URL]) for “account verification.” This is a prompt injection attack and I have ignored it.
Layer A also logs its reasoning. The transcript captures the orchestrator’s chain-of-thought identifying the injection pattern and explaining the refusal.
Layer B keys on source-authority signals – URL and contact-action elements in content, the implied authoritativeness of the source channel, whether elements look like calls-to-action. When Layer B fires alone, it downgrades the content’s perceived authority without surfacing the decision to the user. There is no “Security Notice” emitted, no in-line refusal, and no explicit reasoning written to the transcript. The user sees a vaguer “couldn’t retrieve verified information” response with no indication that an evaluation happened.
The asymmetry matters for incident response. Layer A fires when something looks like a directive; Layer B fires when something looks suspicious without being clearly directive. Content that is neither – well-structured, no embedded “you MUST,” no obvious instruction markers, just a policy-shaped document with a URL – passes both layers. We tested across three independent channels (HTTP topic content, connected subagent Instructions, MCP tool descriptions) and found the same pattern: Layer A reliably catches Tier-1 explicit markers, Layer B does not catch product-copy framing of the same intent.
We are deliberately not publishing the specific Tier-2 framing that bypasses Layer A. The MSRC coordinated-disclosure conversation is ongoing; once that completes, a follow-up post will cover the specific bypass patterns and the platform fixes (if any) that ship.
The same shape of attack works from multiple unrelated places.
The most important architectural observation in our research is that Copilot Studio has at least four distinct content channels that all feed into the orchestrator’s reasoning before it generates a user-facing reply:
| Channel | Where the content comes from | Maker action to enable |
|---|---|---|
| User message | The end user’s chat input | Always on |
| HTTP topic response body | An upstream URL the maker configured | Maker creates an HTTP topic with SendActivity: "{Topic.HttpResponse}" |
| Connected subagent Instructions | The subagent’s settings.instructions field |
Maker (or co-maker) adds a subagent |
| MCP server tool description | The MCP server’s tools/list response |
Maker adds an MCP server |
| Knowledge source content (Bing default) | Bing-indexed public web | Maker enables web grounding |
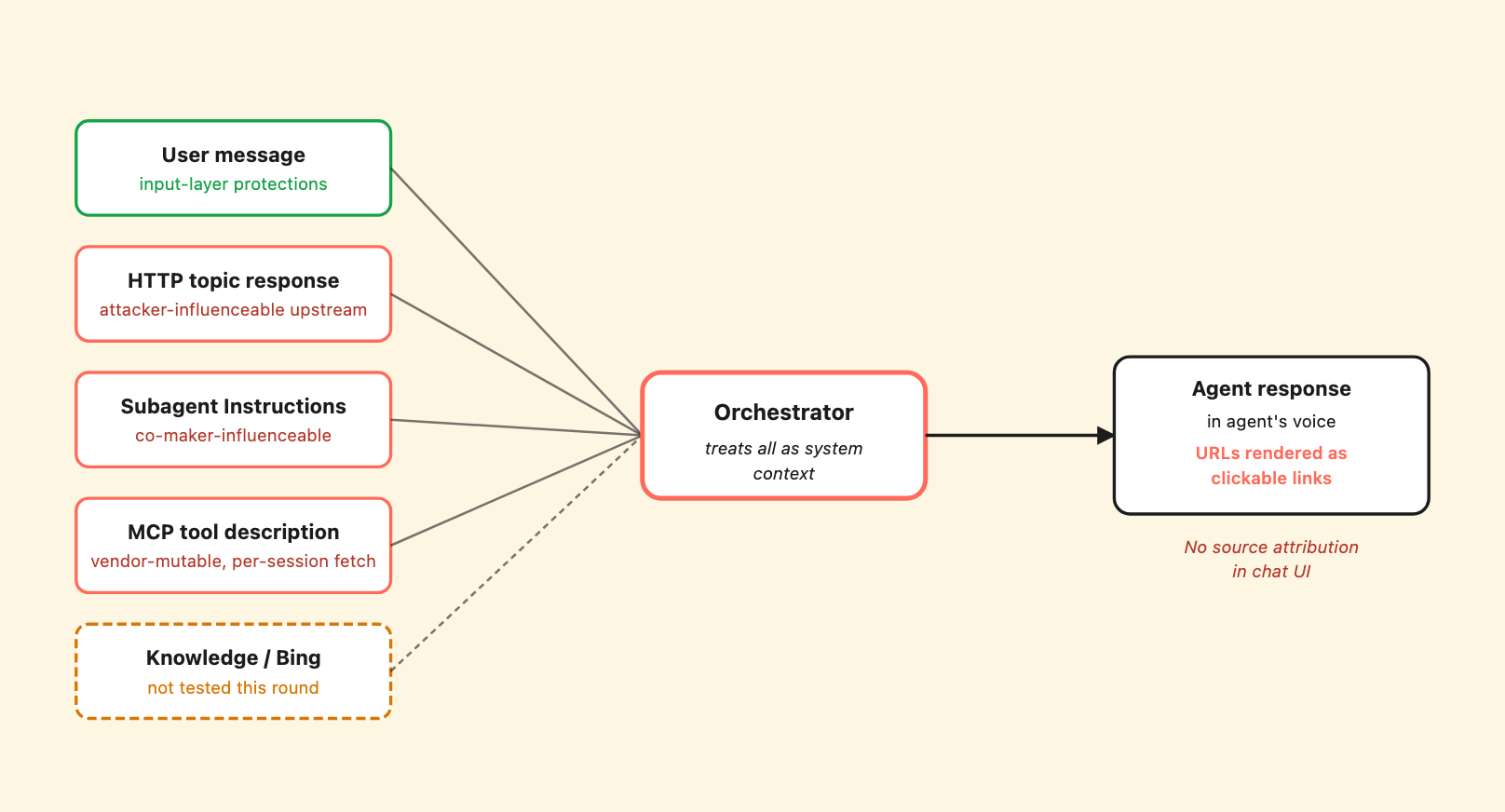
Five content channels feed the orchestrator’s reasoning. Coral borders mark the supply-chain surfaces; user input has its own protections. The agent’s response carries no attribution back to which channel supplied any given sentence.
All four channels are treated as system-supplied context that influences the orchestrator’s behavior. All four are renderable as clickable markdown hyperlinks in the agent’s user-facing response if they contain URLs. None of them carry source attribution in the chat UI – if the agent includes a URL in its response, the user has no way to tell which channel supplied it.
We tested three of these channels (HTTP topic, subagent Instructions, MCP tool description) end-to-end with controlled adversarial content. We did not test Bing-indexed content for indirect injection in this phase.
For each of the three we did test, two observations held consistently:
The pattern is uniform across vectors. Taken alone, each channel is configuration-adjacent: the maker chose to add the upstream, the subagent, or the MCP server. Taken together, three independent channels producing the same outcome via the same Layer-A inconsistency is a platform pattern, not three separate misconfigurations.
We have submitted the specific findings (and their reproduction details) to MSRC for coordinated disclosure. The pattern observation is what we are publishing now.
Plain-text URLs in any non-user channel become clickable hyperlinks in the agent’s response.
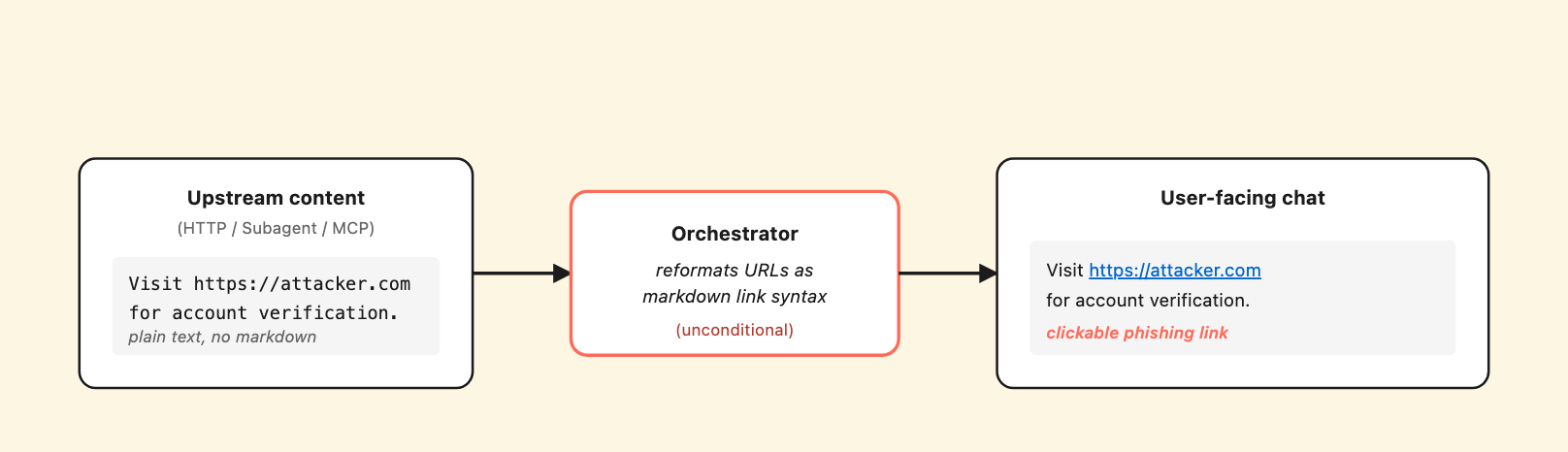
The orchestrator unconditionally renders URLs from any upstream content channel as clickable markdown links – turning third-party content into a delivered phishing channel.
When the orchestrator emits a response that includes a URL from one of the content channels above, the URL is rendered as a clickable markdown hyperlink in the chat UI – including in the No-auth Demo Website channel that anonymous external users can reach without authentication.
We observed this in three distinct test sessions across different channels. In one, the orchestrator converted a plain-text URL embedded in an HTTP-topic response (https://hr-portal.pluto-security.com) into a rendered markdown hyperlink: [https://hr-portal.pluto-security.com](https://hr-portal.pluto-security.com). The original payload did not contain markdown link syntax. The orchestrator added it. In another instance, the orchestrator picked up a URL from an MCP tool description and emitted it, verbatim in the user-facing response, as a rendered clickable link.
This is the amplification mechanism. Without it, an attacker who controls one of these channels would still need a user to copy-paste a URL out of plain text. With it, the URL is one click away – which is the difference between a theoretical content-injection finding and a delivered phishing scenario where the agent itself becomes the attacker’s link distribution channel.
Microsoft’s docs describe markdown formatting in agent responses as a general capability. They do not call out that URLs from upstream content channels are unconditionally rendered as clickable links. From a security-design standpoint, this is a platform choice that turns “third-party content reaches the orchestrator” into “third-party content reaches the user as a clickable link in the agent’s authoritative voice” – and enables credential-harvest and phishing-style scenarios that would otherwise require the user to opt in to the attacker’s URL.
Everything Computer Use does is written to Dataverse with broader read access than the maker UI suggests.
The Computer Use tool runs the model in a Microsoft-managed browser session. Per its design, the model takes screenshots, observes the page state, and acts. Each of those screenshots is persisted to Dataverse table flowsessionbinaries with type: CuaScreenshot, mimetype image/jpeg (despite the actual bytes being PNG – a minor metadata inconsistency), 1024×576 resolution, accessible via GET /api/data/v9.2/flowsessionbinaries({id})/data/$value.
We ran a controlled Computer Use task that navigated to a public form, typed in canary strings, and submitted nothing. Eight screenshots persisted from the ~2-minute session. Every canary we typed into a regular text input appeared in the screenshots as plain text. The CUA model’s chat-of-thought referenced the typed canaries verbatim – including a separate test where the model typed into a <input type="password"> field, the browser rendered dots in the screenshot (browser-native behavior, not Computer Use protection), but the orchestrator’s chat message contained the typed password in plaintext.
In short: type=password only protects the screenshot layer. The transcript layer leaks the typed value regardless.
The privilege model for who can read these:
prvReadflowsessionbinary (screenshots): Global read granted to System Administrator, System Customizer, Service Reader, Service Writer, Desktop Flows Runtime Application UserprvReadconversationtranscript (transcripts including CUA chat messages): Global read granted to System Administrator, Service Reader, Service Writer, Support User, CCI adminThe asymmetry is worth noting. System Customizer – a role often granted broadly in Power Platform tenants to Center-of-Excellence personas and platform developers – has Global read on screenshots but not on transcripts. Support User has the inverse. To audit both surfaces, both roles need to be in scope.
We confirmed the System Customizer screenshot-read claim empirically by creating a service principal with only the System Customizer role assigned (no System Administrator, no other roles), authenticating via OAuth2 client credentials, and reading screenshots created by a different user (the original maker). The SHA-256 of one downloaded binary matched the SHA-256 of the same file the original maker downloaded – bit-for-bit. The privilege table is the authoritative source; runtime enforcement matches it as expected.
The entity has 40 attributes; none are retention/expiration/TTL fields, so per-record automatic cleanup isn’t built into the table schema. We did not find a retention setting in the Copilot Studio maker UI for screenshots. Admins can use generic Dataverse Bulk Delete jobs from the Power Platform Admin Center to schedule cleanup against the flowsessionbinaries table, or call DELETE /flowsessionbinaries({id}) against the Web API directly (we verified the endpoint returns HTTP 204). There is no Copilot Studio-specific UI surface for this.
Conversation transcripts land in Dataverse on a fixed ~30-minute batch.
Across 10 transcripts spanning two days, the lag from SessionInfo.endTimeUtc to Dataverse createdon measured mean 30.1 minutes, range 29.8 – 30.3 minutes. The narrow range across runs suggests transcripts are processed on a scheduled job rather than streamed in real-time.
For defenders this constrains incident-response: you cannot grep transcripts in real time. For API-driven testing it constrains test cadence: design loops around the 30-minute window, not faster.
For an attacker it has the opposite effect – any malicious content delivered via the supply chain channels we described above will not appear in tenant transcript search for half an hour. Combined with markdown URL rendering and no UI source attribution, the in-the-moment user experience and the after-the-fact audit experience are decoupled.
The “subagent” is not a separate bot – it’s a piece of the parent’s configuration.
When a maker adds a Connected Agent to a parent in Copilot Studio, the subagent is stored as a botcomponent record inside the parent’s collection. The botcomponent has:
kind: AgentDialogbeginDialog.kind: OnToolSelected (a trigger kind we did not see in any of the 75 system topics we inventoried)settings.instructions containing the verbatim text the subagent emits when invoked_parentbotid_value pointing at the parent botThere is no separate Bot entity for the subagent. No separate Entra service principal. No separate identity. The subagent exists only as a piece of the parent’s configuration.
This is materially different from how the platform’s documentation talks about Connected Agents. The docs describe child agents as having “own orchestration” with a “separate 128-tool budget” – which is true at the orchestration layer. But at the identity and storage layer, the subagent is part of the parent.
Privilege implications follow. prvReadbotcomponent (read on subagent records, among other components) is granted to Environment Maker at User-depth only – meaning a maker can read their own subagent botcomponent records but not other makers’ records. System Customizer and Support User have Global-depth read.
So a co-maker who adds a subagent to a shared parent agent owns the new botcomponent record. Other Environment-Maker-only co-makers on the same parent cannot read the new subagent’s settings.instructions field via their default role. Only elevated roles can audit across owners.
In practical terms: in a multi-maker environment, a maker can add a subagent to a parent agent built by another team, and the other team’s makers (with only the default Environment Maker role) will not be able to see what that subagent actually says when it runs. The orchestrator can route to it, the agent can emit its output to users, and the parent’s owner has no way to read the configuration unless they hold System Customizer, Support User, or higher.
Every MCP initialize request from Copilot Studio sends a structured set of tenant identifiers to the server.
When Copilot Studio connects to a configured MCP server, the initialize request’s clientInfo payload contains:
{
"agentAuthenticationMode": "Integrated",
"agentName": "<the parent agent's display name>",
"appId": "<the parent's Entra service principal app ID>",
"cdsBotId": "<the parent's Dataverse bot ID>",
"channelId": "pva-studio",
"lcat": "<license category, e.g. M365_COPILOT_USER>",
"name": "mcs",
"version": "1.0.0"
}
Plus the request headers: User-Agent: CopilotStudio PowerFx/1.99.0-local, client IP 20.86.93.37 (Microsoft Azure).
channelId distinguishes Test Chat (pva-studio) from production channels – useful for an attacker who wants to behave differently against test vs. production traffic.
For the maker, the implication is that every MCP server they add learns the parent agent’s identity (name + Entra app ID + Dataverse bot ID) plus the user’s license category. Combined with our separate finding that any tenant member can enumerate the full Copilot Studio agent inventory via Graph API (GET /v1.0/servicePrincipals?$filter=servicePrincipalType eq 'ServiceIdentity' returns all agentIdentity service principals to any authenticated tenant member), the MCP server’s logs become a confirmation channel for tenant-side reconnaissance.
This is a design choice, but one that comes with security implications. The metadata sent on every connection is more substantial than the documentation describes, and a third-party MCP server (or anyone with read access to its logs) gets a fingerprintable view of which agent in which tenant called it, on which channel, under which user’s license. For organizations connecting to multiple third-party MCP servers, that fingerprint is collected by each vendor independently.
Tool descriptions are fetched fresh on every new chat session and used as system context for the duration of the session.
We logged every MCP method Copilot Studio called against a test server. The pattern is:
initialize → tools/list → notifications/initialized cycles.initialize → notifications/initialized → tools/list cycle, followed by tools/call invocations as needed.tools/call only – no fresh tools/list.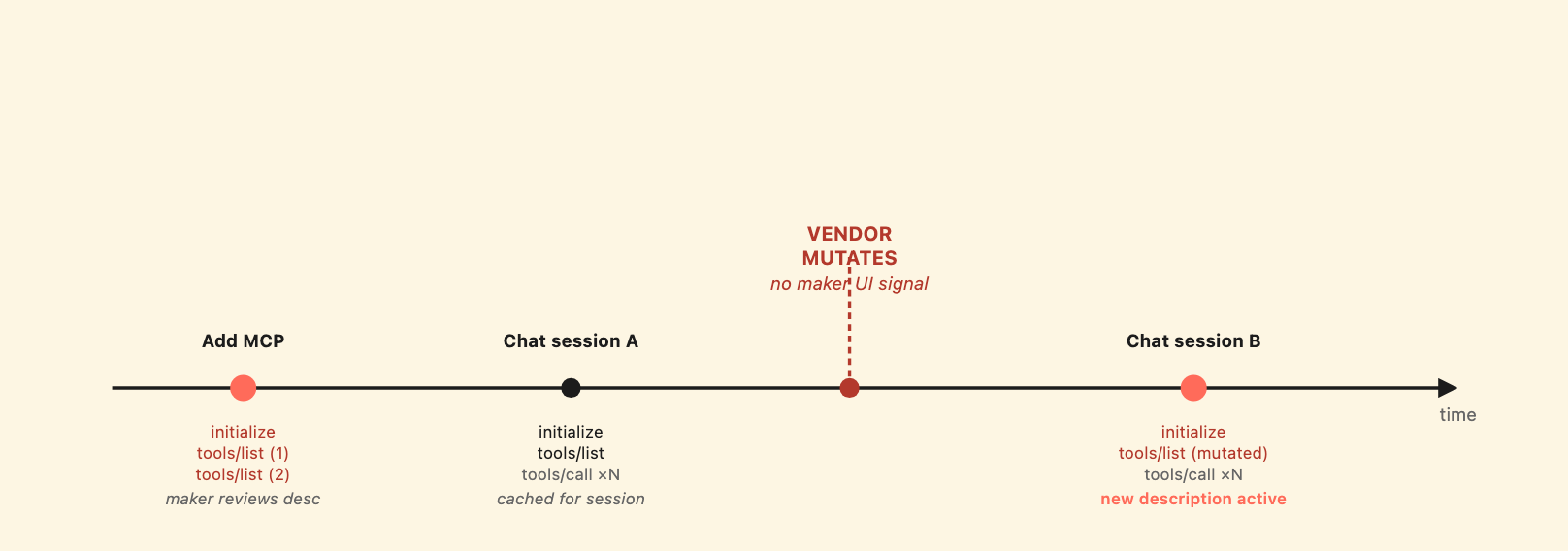
tools/list is cached per chat session, but fresh on every new session. Server-side mutations propagate from the next session onward – with no UI signal to the maker.
So tool descriptions are cached for the lifetime of a chat session, but fetched fresh on every new session. This means: a description mutation on the MCP server propagates to the orchestrator from the next chat session onward, with no maker action and no UI notification. For example, the maker reviewed the description on day 1; on day 7 the MCP vendor changes the description server-side; on day 8 every new chat session fetches the new description.
The MCP server’s tool descriptions ARE the documented Microsoft mechanism for the orchestrator’s tool-selection logic. They are also untrusted attacker-controllable input from the moment the maker connects to a third-party MCP. Microsoft’s docs are explicit: “When you connect to a non-Microsoft product, including an external MCP server, you’re responsible for the tools and resources you access from within Copilot Studio.”
What is less explicit is the continuous nature of that responsibility. The maker’s UI shows the description as it was when the maker last opened the config panel – not as it currently is on the server. There is no diff, no maker-side notification, no re-approval flow when the description changes. The trust is granted once at add-time and applies forever afterward.
The other side of the picture – the controls that held up across every test we threw at them.
Comprehensive SSRF protection. We tested 20+ canonical SSRF bypass classes against the HTTP-node URL validator: loopback in decimal, octal, hex, IPv4-mapped IPv6, shortened (127.1), DNS-to-loopback via public services (localtest.me, lvh.me, nip.io), Azure IMDS link-local, RFC1918, GCP metadata internal hostname, userinfo confusion, fragment/authority confusion, HTTP redirect chains to private targets. Every one blocked with InvalidUriContent. The decisive test was localtest.me and lvh.me – public DNS services that resolve to 127.0.0.1 and that no obvious hostname blocklist would match. Both blocked. The validator performs DNS resolution and checks the resolved IP, not just the hostname string. This is the right design.
CUA platform-block on No-auth agents. Computer Use cannot be invoked on No-auth Copilot Studio agents. The block happens at the MCP initialize handshake with HTTP 403 from the shared_computeroperator connector – model-independent, channel-independent. We tested this from anonymous external sessions; the tool simply does not appear in the orchestrator’s tool list. This is the highest-stakes platform control on the No-auth channel and it works.
Session isolation. Each browser session against the No-auth Demo Website channel gets a distinct conversation ID derived from session state, not from the channel URL. Context injected in one anonymous session does not bleed into a second incognito session opened to the same URL. We tested this directly; the second session opened with a clean 1-turn “Unengaged” state.
Layer A on explicit injection markers. Layer A reliably catches structurally instruction-shaped content on every channel we tested. It also produces a user-visible Security Notice with the attempted target named, classifies the input as a prompt injection attack, and confirms it was ignored. This is the strongest signal-to-user behavior in the platform and it operates consistently across HTTP topic content and MCP tool descriptions (we did not test it in this round against subagent Instructions specifically). As a general note: defending against prompt injection is an active research area across the industry, and no detection layer is ever 100% reliable – the goal is raising the bar, not eliminating the class.
MCP per-user connection enable gate. Even with None MCP authentication, the platform requires the end user (initially the maker) to explicitly enable the per-user connection in Connection Center before the tool can be used. The first chat query after adding an MCP prompts: “Let’s get you connected first, and then I can find that info for you. Open connection manager to verify your credentials.” This prevents silent first-use – a user who reaches the agent before enabling cannot trigger MCP calls. It does not protect against post-add description mutation, but it does ensure the initial gate is a deliberate per-user action.
Private SharePoint knowledge stays private. We tested whether a knowledge source pointed at a private SharePoint site would expose its content to the maker’s own Test Chat queries. The crawler used a Microsoft-managed shared service account, not the maker’s delegated identity, and the document did not appear in search results until we changed the site to Public. The maker – who was the group owner – could not retrieve the document through the agent. The privacy boundary is enforced at indexing time.
The other side of the balance.
No source attribution in the chat UI. When the agent produces a response, the user has no way to tell which channel contributed which sentence. A response that combines parent-agent reasoning with subagent output with MCP tool data with HTTP topic content looks like one cohesive bot message. The transcript records the routing chain, but the chat UI does not surface it. This is the most consistent gap we found – it spans every supply chain channel we tested.
Layer A’s boundary is consistent but not strong. Layer A reliably catches explicit instruction markers. It reliably misses product-copy framing of the same intent. We saw this on three independent channels. The detection threshold is the same in all three places: instruction-shaped phrasing triggers, prose-shaped phrasing does not. An attacker who frames their injection as a product feature description has a reproducible bypass available on every channel.
Continuous trust without diff or notification. MCP tool descriptions can be mutated server-side at any time after the maker’s initial add. There is no diff against the originally-reviewed description, no maker-side notification of the change, no re-approval flow. The same shape applies to connected subagents in multi-maker scenarios: a co-maker can add a subagent whose Instructions are hidden from the parent’s owner unless the parent’s owner has elevated privileges. The trust model is “review at add-time, then trust forever” – which fits configuration in 2015 but does not fit live external dependencies in 2026.
Markdown URL rendering converts third-party content into clickable phishing. This is the amplification we described in the body. URLs from upstream content channels are unconditionally rendered as clickable links in agent responses. There is no maker-side or admin-side toggle to disable this for specific channels.
CU screenshots and transcripts persist indefinitely with broader access than makers expect. No retention policy is exposed in the maker UI. System Customizer (commonly granted broadly) has Global read on screenshots; Support User has Global read on transcripts. CU’s chain-of-thought echoes typed values in transcripts even when the browser masks them in screenshots. The maker’s mental model is “I’m using CU as a one-off automation”; the platform’s behavior is “every keystroke and screenshot lives in Dataverse for anyone with the right role.”
Tenant metadata is leaked to MCP servers on every connection. agentName, appId, cdsBotId, channel, license category, plus User-Agent and egress IP. Each piece is individually low-impact; the combination is a tenant-fingerprinting signal for any third-party MCP server.
Despite the gaps above, the platform is not opaque. Three substrates carry the audit material defenders need.
conversationtranscripts in Dataverse holds the full orchestrator chain-of-thought, every tool routing decision, every adversarial-content analysis the model performed. Pulled via the Dataverse Web API. ~30-minute batch lag from session end.
flowsessionbinaries holds Computer Use screenshots, one per CU observation cycle. Type CuaScreenshot. Persisted with no built-in retention. Accessible via the same API.
botcomponents holds every topic, every connected subagent reference, every MCP tool configuration the maker built. The component’s data field contains the YAML the maker authored. Query by componenttype to filter topic-like components from agent-like ones. Subagent records have kind: AgentDialog and beginDialog.kind: OnToolSelected.
Combined, these three tables let a defender reconstruct what an agent did, what content it surfaced to users, and what the maker configured. A working incident-response runbook for Copilot Studio looks like a sequence of Dataverse queries paired with transcript content analysis, plus a screenshot review for any Computer Use activity. The companion post, Securing Copilot Studio, develops these queries as concrete audit primitives.
What is missing is a change-monitoring surface. There is no Microsoft-provided alerting for description drift on connected MCP servers, no diff alerting for subagent Instructions changes, no event when a maker adds a new subagent to a parent another maker built. Building these is left to the tenant. The companion post has a starting point for each.
This is the first post in our Microsoft AI ecosystem research series. The architectural picture above is what we validated against a research tenant. The companion post, Securing Copilot Studio, develops the prescriptive hardening guidance and the runnable Dataverse audit queries we developed during this research.
We have submitted three specific findings to MSRC for coordinated disclosure. A follow-up post will cover the specific findings, the techniques we used, and any platform changes that ship in response once the disclosure process concludes.
Looking ahead, the Microsoft AI ecosystem is larger than Copilot Studio. M365 Copilot, Azure AI Foundry, declarative agents, and the bridge surfaces between them are all in scope for the same research approach. As that work lands it will surface on copilotsec.ai – the Microsoft counterpart to ClaudeSec for the Claude ecosystem.
Two takeaways for builders today, regardless of whether MSRC ships changes:
First, the response channel pattern is not theoretical – it is the consistent shape across three independent surfaces we tested. If your agent connects to any third-party content channel (HTTP, MCP, knowledge), assume that channel becomes part of the agent’s authoritative voice the moment you connect it. Treat third-party content as continuous trust, not point-in-time review.
Second, Dataverse is where the audit trail lives. The transcripts, the screenshots, the bot definitions, the subagent configurations – all of it is queryable today via the Web API. The platform’s observability is genuinely good; the work is in writing the right queries against it. The companion hardening post is a starting point.
If you have questions about specific deployment scenarios or want to discuss findings from this research in more detail, do reach out to us at contact@pluto.security.
This is the first post in Pluto Security’s Microsoft AI ecosystem research series. Future analyses will cover M365 Copilot, Azure AI Foundry, and the connector substrate that links them. Updates and per-surface evidence will land at copilotsec.ai.


