Large language models are now part of normal application stacks. They answer questions against internal data, generate code, summarize records, and trigger actions in connected workflows. That usefulness also creates a different security problem, because the model is no longer working in isolation. LLM security is really about controlling how the model interacts with data, tools, and users once it is embedded inside real systems.
What is LLM Security?
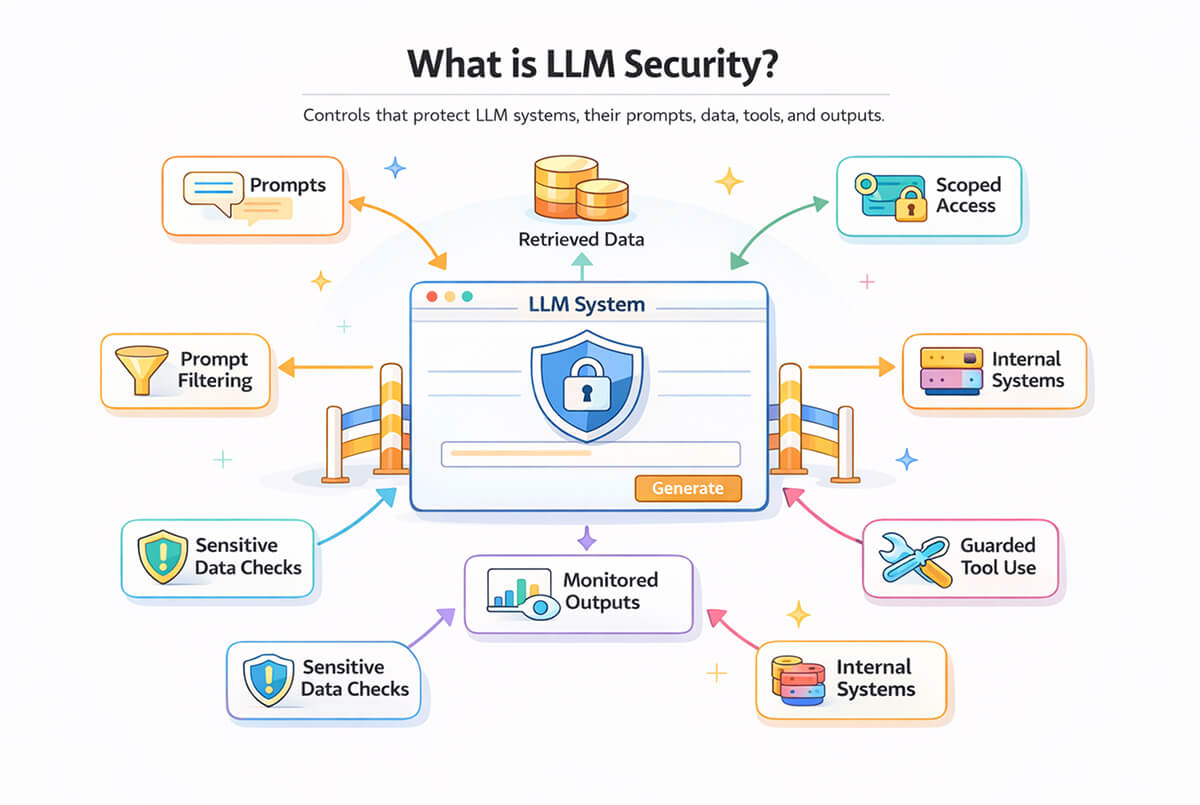
LLM security is the set of controls used to protect applications built on large language models. That includes the model, the prompts sent to it, the data retrieved for context, the tools it can call, and the systems around it.
The model is only one part of the risk. In production, it is usually connected to retrieval layers, internal APIs, document stores, or workflow engines. A chat assistant may read customer records, an internal agent may call backend services, and a coding assistant may inspect private repositories. Once that happens, the security question shifts from model behavior alone to how language-driven systems cross trust boundaries.
That is where most LLM security work sits. It is less about protecting a single model endpoint and more about ensuring prompts, context, tool calls, and outputs stay within the proper limits.
Key Security Risks Associated with Large Language Models
Some LLM security risks are familiar. You still have to think about access control, secrets handling, logging, and third-party exposure. But large language models change the way those problems appear, because plain language can influence retrieval, action selection, and output generation.
A few issues tend to show up repeatedly:
- Overexposed data access – The system retrieves more internal content than the user should be allowed to see.
- Prompt injection – Untrusted text affects the model’s behavior or overrides intended instructions.
- Sensitive output leakage – The model returns secrets, internal content, or customer data in its responses.
- Tool misuse – The model selects or parameterizes actions that were never intended to be allowed.
- Weak observability – Teams cannot explain why the system produced a particular answer or action.
These failures usually come from ordinary implementation choices, not spectacular exploits. For example, a retrieval layer gets scoped too broadly, a tool is exposed without strong validation, or a system prompt is treated like a hard policy boundary. Then the application meets real user behavior, mixed-trust content, and messy data.
One thing teams learn quickly is that a carefully written prompt does not behave like an enforcement layer-it can guide the model, but it cannot reliably contain it. If the surrounding system has access to sensitive data or privileged tools, the actual protection has to come from architecture and control points outside the model.
Data Leakage and Prompt Injection in LLM Systems
Data leakage is usually the first issue teams focus on. An LLM application can expose sensitive data without looking broken, especially when retrieval and generation behave as expected. A retrieval assistant may return documents outside the user’s permission scope. A coding tool may surface secrets from configs. A support workflow may send customer data to an external model API without proper filtering.
This is where LLM data security becomes an engineering concern tied to prompts, retrieval boundaries, output handling, and access checks.

Prompt injection works differently. The model follows trusted instructions but also reads untrusted text from users, documents, or web content. That text can try to override the task or influence tool use.
In connected systems, this can affect retrieval and actions. For example, a finance assistant may retrieve a malicious document that pushes it to request full exports instead of filtered summaries. If tool parameters are not validated, the workflow can be steered by that input.
Building Practical Controls
The controls that help most are usually not complicated. They are mostly about narrowing permissions, reducing ambiguity, and moving critical decisions out of the model where possible.
A safer application often has a few consistent traits:
- Retrieval scoped by identity – The model only sees documents that are already filtered by the user’s access rights.
- Tool calls behind validation – The model can suggest actions, but fixed schemas and policy checks decide what is allowed.
- Output inspection – Responses are checked for secrets, sensitive fields, and known restricted patterns.
- Clear trust separation – User input, retrieved content, and system instructions are handled as distinct classes of input.
Those controls do create tradeoffs. Tighter retrieval filters can lower answer quality. Extra validation can make an agent less flexible. Approval steps can slow a workflow. Still, those are ordinary software tradeoffs, and they are easier to manage than a system that quietly leaks data or performs the wrong action.
Monitoring is another area teams often underestimate, which is why some organizations add AI workspace security layers such as Pluto Security to gain real-time visibility, understand risk, and apply guardrails around AI-driven workflows. When an LLM feature fails, the path to that failure is usually hard to reconstruct unless prompts, retrieved sources, tool decisions, policy checks, and outputs are logged in a reviewable way. Without that, debugging turns into guesswork, and post-incident review stays shallow.
Security Work That Actually Helps
Many teams start by hardening prompts because it is easy to ship. That is useful, but it is only one layer and should not be the main defense. The work that helps more is usually structural. Give the model the minimum data needed for the current task. Treat retrieved content as untrusted. Put deterministic checks in front of sensitive actions. Restrict tool permissions. Test the system with adversarial prompts before release, not after a problem appears in production.
It also helps to review LLM features the same way you would review any backend integration. Ask what the model can read, what it can send, what it can trigger, and what happens if the prompt is manipulated. That framing exposes LLM security risks more quickly than a broad discussion of model intelligence or alignment.
Final Thoughts
LLM security is not separate from application security. It sits in the data flow, the permission model, the prompt path, and the controls around tool usage. The model changes the shape of the problem, but the practical response still comes from careful engineering.
Most LLM security work gets clearer once the model is treated as useful but unreliable. That view tends to yield better system boundaries, more consistent review habits, and fewer surprises when the application runs against real data.
