
Traditional application security usually starts with code, dependencies, APIs, infrastructure, and runtime behavior. That still matters because an AI agent is still software.
The difference is that an agent can interpret instructions, call tools, read context, make decisions, and produce actions that were not hardcoded as fixed branches in the codebase. That changes the security model. A normal web app fails when input handling, access control, dependency management, or deployment configuration breaks. An AI agent can fail even when those controls appear to be in place.
Why AI Agents Require a Different Security Approach
Traditional AppSec assumes that applications have predictable paths. A request comes in, business logic runs, permissions are checked, and data is returned or changed. You can test many of these paths with SAST, DAST, dependency scanning, API testing, and runtime monitoring.
AI agent security has to deal with softer boundaries. The agent receives natural language, retrieves context, reasons over it, and may decide which tool to use next. A user prompt, a knowledge base document, or a response from another system can influence the agent’s next step.
That creates a problem AppSec teams are not accustomed to handling cleanly. The attacker does not always need to exploit a code bug. They may only need to influence the agent’s instructions.
Key Differences Between AI Agent Security and Traditional AppSec
When comparing AI security and application security, the main difference is not that older controls stop mattering. They still matter. The difference is that agents introduce new failure points around prompts, context, tool use, memory, and model-driven decisions.
Traditional AppSec focuses heavily on implementation flaws. AI agent security also needs to handle behavior flaws.
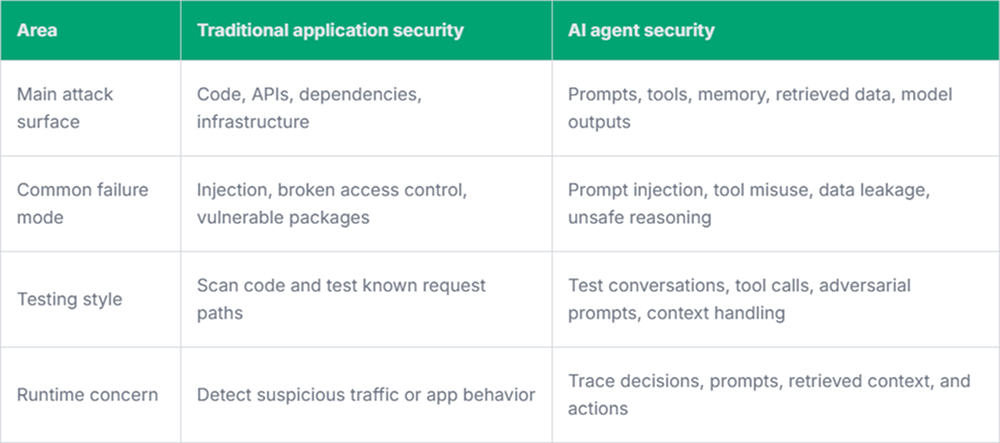
Prompt Input Is Not Just User Input
Web developers already know not to trust user input. With agents, the definition of input gets wider. A prompt can come from a user, but instructions can also be hidden inside emails, documents, web pages, tickets, chat logs, or database records. If the agent treats retrieved content as trusted instructions, it may follow something the developer never intended.
To secure AI agents, teams need to more carefully separate instruction sources. System instructions, developer rules, user requests, retrieved content, and tool outputs should not all have the same authority.
A few controls help here:
- Instruction hierarchy: The agent should know which instructions are trusted and which are only data.
- Tool permissions: The agent should not have broad access to every internal action by default.
- Output checks: Sensitive data, policy violations, and unexpected tool calls need review before execution.
- Conversation tracing: Security teams need logs that show prompts, retrieved context, decisions, and tool use.
Tool Use Changes the Risk
An AI chatbot that only answers questions faces a specific risk. An agent that can send emails, create tickets, update records, run queries, or trigger workflows has another. The dangerous part is not always the model response. Sometimes it is the action taken after the response.
Traditional AppSec often focuses on whether an API endpoint is protected. AI agent security also asks whether the agent should have been able to choose that endpoint in the first place. This is where AI workspace security tools like Pluto Security can be used to provide teams with real-time visibility, risk context, and guardrails for AI-driven workflows.
Testing Needs to Include Behavior
Security testing for agents cannot stop at code review. The code may be clean, while the agent still behaves badly under pressure.
Teams need tests that simulate realistic misuse, not just obvious jailbreak prompts, but also boring business cases. A user asking for another account’s data. A document that contains hidden instructions. A tool response that tries to redirect the agent. A multi-step task where the first answer is safe, but the third action is not.
This testing will not be perfect. Agent behavior can vary. That is why runtime monitoring matters more than usual. You want to know what context the agent saw, why it selected a tool, and what it returned.
Final Thoughts
AI agents still need traditional application security. Authentication, authorization, secure APIs, dependency management, logging, and infrastructure controls do not go away. The difference is that agents add a decision layer that can be influenced through language and context. That layer needs its own controls.